| Line 76: | Line 76: | ||
一般来说有几种缓解维数灾难的方法: | 一般来说有几种缓解维数灾难的方法: | ||
| + | |||
1. ''特征提取''。其实很多人在没听说过维数灾难这个概念之前就已经在解决这个问题了!比如说你想识别一个图像中的人脸。一般人稍微有点儿经验的就不会把全部像素的灰度当成一个巨大的向量拿去给算法当成输入来运行,因为这个向量中参杂的冗余信息太多了。举个例子,加入你有一张100x100的图像,如果不提取特征的话用来进行分类的灰度向量有10000这么长!但是,如果你能运用从图像中提取的边缘,角点信息,就可以把维数降到几百甚至几十,同时只丢掉少量的信息。这种方式的特征选择与提取通常要求一些先验知识,这些知识可以从其他学科而来,比如脑科学,视觉心理学等等。 | 1. ''特征提取''。其实很多人在没听说过维数灾难这个概念之前就已经在解决这个问题了!比如说你想识别一个图像中的人脸。一般人稍微有点儿经验的就不会把全部像素的灰度当成一个巨大的向量拿去给算法当成输入来运行,因为这个向量中参杂的冗余信息太多了。举个例子,加入你有一张100x100的图像,如果不提取特征的话用来进行分类的灰度向量有10000这么长!但是,如果你能运用从图像中提取的边缘,角点信息,就可以把维数降到几百甚至几十,同时只丢掉少量的信息。这种方式的特征选择与提取通常要求一些先验知识,这些知识可以从其他学科而来,比如脑科学,视觉心理学等等。 | ||
Revision as of 18:10, 24 April 2014
维数灾难
部分取材于 ECE662 Spring 2014 lecture Mireille Boutin教授的课堂讲义
稻草堆里捞针
你不小心把针掉到了一个稻草堆里。如果你生活在一个一维世界里,在稻草堆里找到这枚针是一件很容易的事情。因为如果针是一个点,那么稻草堆只能是一条线段。所以你可以从线段的一端开始,朝另一端出发,不停寻找直到在线段某点看到那枚针。

还不算太难,对吧?当然,如果你是一个二维生物,那么这个问题就不是那么简单了,因为现在你要在一个正方形里寻找一个点。

这个正方形里有更多的空间:那枚针可以沿着$ x $轴或者$ y $轴移动。在日常生活中的三维,针变成了正方体里的一个点。

这个找针的问题会随着维数的增加变得越来越难。你或许都已经想象不到假如有生活在超高维度的外星生物存在于宇宙某个角落,当他们丢了东西时,应该怎么寻找?
在高维空间里的稻草堆某一点出发试图找到一枚丢失的针的超高难度说明了一个重要的事实,那就是点在空间中的分布变得越来越离散(也就是说点和点之间的不相似性越来越倾向于变大)。这个结论也很容易从欧拉距离的定义看出来:两个点之间的欧拉距离足够大只要这两个点在至少一个维度方向的差别足够大就行了,虽然不排除这两个点有可能在其他维度方向上十分相似甚至完全相同。我们还可以根据下面这个例子来定量地证明这个结论。在$ N $维空间中,假设我们想在一个边长为1的超正方体中计数某个处于超正方体正中的一个点周围的邻居点个数。同时我们考虑嵌套在这个超正方体外面的一个更大的变长为$ 1+2\epsilon $的超正方体。作为一个特殊例子,在三维空间里我们有:

再假设空间中所有的点都是均匀分布的,那么位于里面那个小超正方体中的点的个数和位于外面那个大超正方体中的点的个数的比值可以表示为:
$ (\frac{1}{1+2\epsilon})^N $
取$ \epsilon=0.01 $,那么对于$ N= $1,2,3,5,10,100和1000,这个比值分别是0.98,0.96,0.94,0.91,0.82,0.14和$ 2.51\text{e}^{-09} $。可以看出当$ N >= 10 $的时候,这个点周围已经基本上没有邻居在较小的超正方体里了,大部分的点都集中在了围绕它的那个厚度$ \epsilon $的“壳”里。如果要想继续保持一定数量的邻居点,那么所有点的个数必须成指数增加。
维数灾难
数学定理通常都能很轻易地从低维一般化到高维。这就是为什么如果你懂得如何计算两个变量的函数的梯度导数,你基本上就知道怎么计算含有成千上万个变量的函数的梯度。但是在机器统计学习里,你会发现你高高兴兴地写了一个拟合二维概率密度函数的算法,却发现基本上不能直接用在高维空间中。理论上来说,你的算法确确实实经过维数的小改动可以原封不动地拿到高维里去用,但是前提条件是你必须要有足够的指数增长的训练数据。然而实际情况中,训练数据通常有限,训练点在空间中分布稀疏。
这些有限的训练数据不能很好地让你的算法工作的原因不是因为你算法出了理论上的问题,而是因为他们因为太稀疏从而根本就不统计显著。也就是说,训练数据提供给你算法的信息太少了所以很难估计到正确的概率模型。统计显著这个概率可以进一步用下面一个一维空间中的简单例子来说明。假如你从一个正态分布中抽取一定数量的点来估计这个分布的均值和方差。这个分布如下:

如果你只抽取了10个点得到的结果:

如果你抽取了100个点:

可以看出抽取10个点和抽取100个点相差非常大。因为在10个点的情况下,那10个点可能并不能很好地代表整个空间中点的分布情况。所以你的算法结果只取决于抽签运气好不好了。
维数灾难指的就是因为正常情况下在高维空间中获取足够训练数据基本上不可能所以很难准确估计出高维空间中的概率密度函数。用上面一维的例子来进行类比,就是假如你突然中了诅咒,每次用来训练的数据量不能超过10个,否则你的电脑就会死机。即使你不估计概率密度函数,而是直接通过分类器来寻找不同类别之间的决策边界,你根本就没办法知道到底在有限的训练集上得到的决策边界仅仅是能够将这些特殊的不能代表整个空间中点分布的数据区分开还是能够一般化到整个数据空间。这种不能准确地估计并且一般化到未知数据的情况被称为过拟合。即使在低维空间中有足够的训练数据,过拟合还是会发生(比如因为过度复杂的概率模型,不科学的数据采集方法等)。但是过拟合在高维空间中更容易发生因为通常都没有足够的训练数据。
一般来说有几种缓解维数灾难的方法:
1. 特征提取。其实很多人在没听说过维数灾难这个概念之前就已经在解决这个问题了!比如说你想识别一个图像中的人脸。一般人稍微有点儿经验的就不会把全部像素的灰度当成一个巨大的向量拿去给算法当成输入来运行,因为这个向量中参杂的冗余信息太多了。举个例子,加入你有一张100x100的图像,如果不提取特征的话用来进行分类的灰度向量有10000这么长!但是,如果你能运用从图像中提取的边缘,角点信息,就可以把维数降到几百甚至几十,同时只丢掉少量的信息。这种方式的特征选择与提取通常要求一些先验知识,这些知识可以从其他学科而来,比如脑科学,视觉心理学等等。
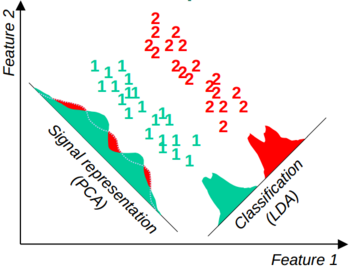
2. 简化维数。人们提出一些统计方法来自动简化维数。根据需求的不同,简化的结果通常区别较大。如果目标是将原来高维空间的数据在低维空间中尽可能准确地表示出来(丢去少量信息),那么在一个类别中特征值方差最大的方向会被保存下来,也就是主成分分析法(PCA)。如果目标是在低维空间中最好地区分不同的类别,那么在类别之间特征值分布相对分离的方向会被保存下来,也就是线性判别分析法(LDA)。下面这个图(来自 参考文献2)说明了这两种方法的不同。

3. 核。稻草堆中找针|的例子说明了当数据量不足时,高维空间中的每个点看起来都像是某个分布的异常值。直接用分类器处理这些高维空间中的点简直就是痛苦。支持向量机(SVM)中使用的核函数能够自动将数据映射到决策边界更好寻找的高维甚至无限维空间中。这样的映射使得在低维空间中线性不可分的特征在高维空间中线性可分(这也是人们为什么喜欢使用大量数据的原因)。换句话说,你的分类器虽然在很高维度的特征空间中学习决策边界,实际上它只用处理在低维度空间中的参数估计。
所有上面的方法都不是万能之策。维数灾难还是一个有待进一步研究的问题。
参考文献
- http://en.wikipedia.org/wiki/Curse_of_dimensionality
- http://courses.cs.tamu.edu/rgutier/cs790_w02/l5.pdf
问题和评论
如果你有任何问题或者评论,请将它们写在这里。
